作者|Li Yuan
編輯| 鄭玄
?
過(guò)去一年,大模型的世界幾乎是「狂飆」的同義詞。技術(shù)以周為單位迭代,能力邊界從寫詩(shī)作畫,一路拓展到視頻生成和科學(xué)發(fā)現(xiàn)。
然而,拋開那些宏大敘事,我們?cè)撊绾螢?AI 的能力找到一個(gè)精準(zhǔn)、客觀的刻度?
恐怕沒有哪種方式,比「高考」更能直抵每一個(gè)中國(guó)人的內(nèi)心。
去年,極客公園就做過(guò)一期 AI 高考模擬測(cè)評(píng) 。延續(xù)去年的傳統(tǒng),極客公園今年再次搭建「AI 高考」考場(chǎng),讓國(guó)內(nèi)外主流大模型再次走進(jìn)考場(chǎng)。
再次走入考場(chǎng)的「AI 考生」們,不僅 治好了去年文科偏科的毛病 ,還取得了足以考進(jìn)山東省內(nèi) 1000 名的高分。
然而,就在我們以為它已經(jīng)「進(jìn)化」時(shí),它卻又常在意想不到的地方,暴露了自己真實(shí)的「智商」。
一些關(guān)鍵發(fā)現(xiàn)如下:
- AI 首次有望沖擊頂尖學(xué)府 : 今年,AI 的綜合能力首次展現(xiàn)出足以考上頂尖學(xué)府的潛力。與 2024 年相比,所有參與測(cè)試的大模型在文理科成績(jī)上均實(shí)現(xiàn)了顯著飛躍。由于山東省采取賦分的報(bào)考策略,無(wú)法直接與分?jǐn)?shù)段相比較,我們估計(jì)此次高考的狀元豆包,能夠排進(jìn)全省的 500-900 名,考入人大、復(fù)旦、上海交大、浙大這些名牌大學(xué)的人文社科類專業(yè)。
- 大模型不再嚴(yán)重偏科,理科進(jìn)步更快: 各大模型的文科總分平均增長(zhǎng)了 115.6 分,理科總分平均增長(zhǎng)了 147.4 分。盡管理科的增速更為迅猛,但其 181.75 分的平均總分仍低于文科的 228.33 分。總體來(lái)看,今年大模型的總分表現(xiàn)已不再嚴(yán)重「偏科」。
- 數(shù)學(xué)能力大幅增強(qiáng),超越語(yǔ)文、英語(yǔ): 數(shù)學(xué)是本年度進(jìn)步最顯著的科目,平均分較去年提升了 84.25 分。AI 在數(shù)學(xué)上的表現(xiàn)甚至超過(guò)了語(yǔ)文和英語(yǔ),這預(yù)示著未來(lái) AI 可能更擅長(zhǎng)處理邏輯性強(qiáng)和有標(biāo)準(zhǔn)化解題路徑的題目。
- 多模態(tài)能力成為拉開差距的關(guān)鍵: 去年到今年,模型的視覺理解能力顯著提升,這一點(diǎn)在包含大量圖像題的學(xué)科中尤為突出。與去年相比,物理和地理的平均分提升了約 20 分,生物提升了 15 分。化學(xué)科目整體表現(xiàn)稍弱,僅「豆包」模型及格,但全員平均分也比去年提高了 12.6 分。作為彩蛋,我們今年也嘗試讓 AI 在視頻流中答題。
?
01
從一本到頂尖大學(xué)
?
如果說(shuō)去年的 AI 還只是一個(gè)剛摸到一本線的優(yōu)秀生,那么今年,它們已經(jīng)成長(zhǎng)為足以沖擊中國(guó)頂尖學(xué)府的學(xué)霸。
這背后,究竟發(fā)生了怎樣的蛻變?
在深入具體的變化之前,我們先介紹一下此次參與考試的國(guó)內(nèi)外考生:
豆包、 DeepSeek(R1-0528 版)、ChatGPT(o3)、元寶(Hunyuan t1)、Kimi(k1.5)、文心一言、通義千問(wèn)。
為了更貼合讀者的使用體驗(yàn),本次評(píng)測(cè)均在各模型的公開 PC 端進(jìn)行,測(cè)評(píng)采取采樣兩次取平均分的形式。
目的是考察模型的綜合能力,此次測(cè)評(píng)的方式是直接讓模型識(shí)別圖像作答。DeepSeek-R1 目前仍然不支持圖片識(shí)別作答,因此只測(cè)試了純文字題目,最終成績(jī)參考性不強(qiáng)。
其他測(cè)試細(xì)節(jié)如下:
- 此次測(cè)試選用 2025 年新高考山東卷作為本次評(píng)測(cè)的測(cè)試卷。原因有二:首先,山東卷是網(wǎng)絡(luò)上能最快獲取到的高考試卷之一,保證了評(píng)測(cè)的時(shí)效性。其次,它的綜合難度在各省份中名列前茅——其語(yǔ)文、數(shù)學(xué)、英語(yǔ)三科采用全國(guó)一卷,其余科目則為自主命題。這樣一把高難度的「標(biāo)尺」,更能探知當(dāng)前大模型能力的上限。
- 為保證公平并考察模型的通用基礎(chǔ)能力,在可以關(guān)閉模型聯(lián)網(wǎng)能力的產(chǎn)品中,統(tǒng)一關(guān)閉了模型的聯(lián)網(wǎng)功能,以杜絕「搜題」的可能。o3 和文心無(wú)法關(guān)閉聯(lián)網(wǎng),不過(guò)檢查模型思考過(guò)程發(fā)現(xiàn),文心沒有發(fā)生聯(lián)網(wǎng)搜題的情形,o3 發(fā)生少量搜題情形,但沒有明顯收益,得分率反而低于非聯(lián)網(wǎng)答題。同時(shí),我們默認(rèn)開啟了深度思考模式,但沒有開啟研究模式,以模擬用戶在標(biāo)準(zhǔn)交互下的即時(shí)問(wèn)答場(chǎng)景。
- 非選擇題各學(xué)科分別請(qǐng)兩名專業(yè)同學(xué)打分,如存在題目分值 1/6 以上的差異,則引入第三人討論定分(與真實(shí)高考判卷流程一致),并邀請(qǐng)參與過(guò)真實(shí)高考打分的高中老師抽檢,對(duì)存在差異的題目統(tǒng)一標(biāo)準(zhǔn)。
- 在評(píng)分環(huán)節(jié),我們做了兩項(xiàng)特殊處理:我們特邀了資深教師進(jìn)行對(duì) AI 作文進(jìn)行匿名評(píng)審,以保證客觀公正。此外,由于無(wú)法獲取英語(yǔ)聽力部分的試題,我們?cè)O(shè)定所有模型在該項(xiàng)上均計(jì)為滿分。
?
?
?
最終,各位考生的成績(jī)?nèi)缦拢?/p>

過(guò)去一年,大模型的深度思考能力,帶來(lái)了模型能力的明顯進(jìn)步。
模型不再不是直接產(chǎn)出答案,而是逐步分析、分解問(wèn)題、檢查中間結(jié)果,甚至自我修正,帶來(lái)了模型在數(shù)理考試中的表現(xiàn)的大幅提升。
總分為 150 分的數(shù)學(xué)考試中,即便是本次測(cè)試中表現(xiàn)最差的 AI 模型,也拿下了 128.75 分的高分——這在人類考生中也屬于優(yōu)秀水平。
而回顧去年,表現(xiàn)最好的模型,也只達(dá)到了 70 分,連及格線都沒到。
數(shù)學(xué)能力的進(jìn)步,直接帶動(dòng)了今年大模型整體高考成績(jī)的大幅提升。

多模態(tài)能力,成為決定大模型能力表現(xiàn)差別的另一個(gè)關(guān)鍵因素。
在去年的高考測(cè)試中,不少模型還不具備成熟的圖片識(shí)別能力。極客公園當(dāng)時(shí)采用的評(píng)測(cè)方式是:能識(shí)圖的模型使用圖片配合文字輸入,而無(wú)法識(shí)圖的模型則只輸入文字,同時(shí)輔以 Markdown/LaTeX 格式幫助識(shí)別公式。
而進(jìn)入今年,多模態(tài)能力是主流模型的標(biāo)配功能。因此,我們首次在測(cè)試中采用純圖片題目測(cè)試(DeepSeek除外)。
在多個(gè)模型中,豆包、ChatGPT最先進(jìn)的模型都是多模態(tài)版,在圖像問(wèn)題上體現(xiàn)出明顯優(yōu)勢(shì)。
Qwen3、文心 X1 都是語(yǔ)言模型,處理圖像問(wèn)題時(shí)可能是用 OCR 識(shí)別文字后回答,或是調(diào)用視覺模型,在圖像類問(wèn)題上表現(xiàn)較弱。
不過(guò),即使是圖像問(wèn)題得分最高的豆包和 ChatGPT,圖像問(wèn)題的得分率僅為 70%,相比文本問(wèn)題 90% 的最高得分率有較大差距,可見大模型在多模態(tài)理解和推理上仍有很大的提升空間。
可以預(yù)見的是:隨著多模態(tài)能力的持續(xù)進(jìn)步,明年AI的高考成績(jī)還會(huì)繼續(xù)提升。考不過(guò)AI,終將成為大多數(shù)人類的常態(tài)。
然而,AI 終究沒有拿下全滿分的成績(jī)。是什么絆住了學(xué)霸級(jí)的 AI?答案可能比想象中的有趣。
?
02
數(shù)學(xué)逼近滿分的 AI 天才們,
齊齊敗在一道基礎(chǔ)題上
?
在整場(chǎng) AI 高考的測(cè)評(píng)中, 「 AI 考生」復(fù)讀了一年后,在數(shù)學(xué)科目上的進(jìn)步十分矚目。
在 2024 年的測(cè)評(píng)中,當(dāng)時(shí)的 AI 考生們?cè)谔羁疹}和解答題上表現(xiàn)慘淡,得分普遍在 0 至 2 分之間徘徊,最終 9 款參評(píng)模型的數(shù)學(xué)成績(jī)的平均分僅為 47 分。
而今年,則完全不同。

可以看出,無(wú)論是客觀選擇題,還是復(fù)雜的主觀解答題,新一代大模型的正確率都今非昔比。這清晰地表明,大模型自身的能力,尤其是核心的推理能力,已經(jīng)取得了根本性的突破。
如果說(shuō)去年的模型還只是一個(gè)能勉強(qiáng)套用求導(dǎo)、三角函數(shù)等基礎(chǔ)公式的「初學(xué)者」,那么今年的模型,則已經(jīng)進(jìn)化成一個(gè)能夠從容應(yīng)對(duì)復(fù)雜推導(dǎo)和證明的「解題高手」了。
一定程度上,這樣的結(jié)果在預(yù)料之中。自從 AI 進(jìn)入推理模型時(shí)代,一個(gè)標(biāo)志性進(jìn)展便是數(shù)理能力的大幅提升。
當(dāng)模型擁有了自我思考與自我糾錯(cuò)的能力,它就像一個(gè)從前張口就回答問(wèn)題的孩子,成長(zhǎng)為一個(gè)會(huì)先深度思考再給出答案的大人,邏輯能力實(shí)現(xiàn)了質(zhì)的飛躍。
要知道,今年高考新課標(biāo)一卷的數(shù)學(xué)題被考生普遍認(rèn)為難度極高,「像競(jìng)賽卷」,導(dǎo)數(shù)、圓錐曲線等壓軸題思路晦澀,計(jì)算量極大,甚至出現(xiàn)「學(xué)霸考哭」的現(xiàn)象。
然而,面對(duì)這樣一份高難度試卷,頂尖的大模型們依舊表現(xiàn)得游刃有余。
相較之下,AI 的多模態(tài)能力的進(jìn)展倒還在其次。數(shù)學(xué)科目中,只有 20 分的圖像問(wèn)題,不是此次模型大幅度提分的重點(diǎn)。而大多數(shù)模型,也都在圖像題中取得了 15 分的成績(jī)。
為什么是 15 分?
這就很有趣了。這些整體都考了 130 分以上的大模型,放在人類社會(huì)里,也算是數(shù)學(xué)尖子生了,竟然在同一道選擇題上出現(xiàn)了錯(cuò)誤。
難住他們的,不是什么壓軸大題,而是一道單選題——甚至不是很難的單選題。

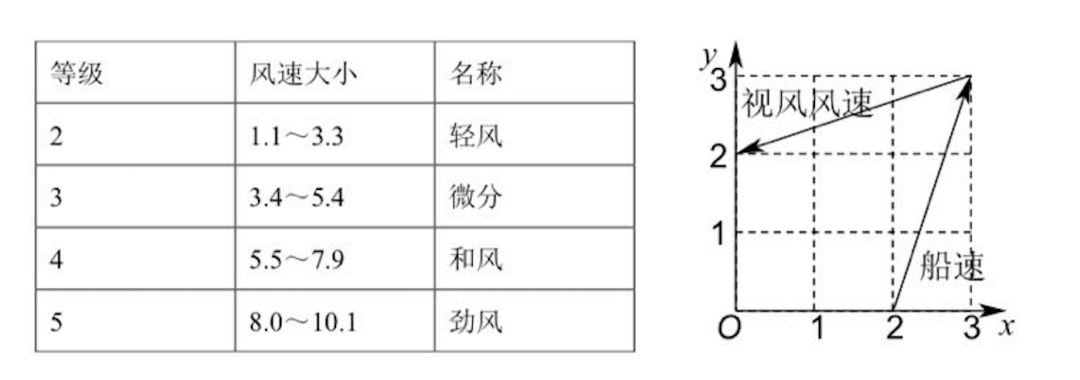
這道題的數(shù)學(xué)原理非常簡(jiǎn)單,是一道基礎(chǔ)的向量加減法題。只需在圖上連接 (0,2) 與 (2,0) 兩點(diǎn),即可得到目標(biāo)向量,模長(zhǎng) 2 倍根號(hào) 2。
即便對(duì)數(shù)學(xué)不甚了解的人,通過(guò)肉眼觀察圖中的線段,也能估算出其長(zhǎng)度不會(huì)超過(guò) 3.3。
然而,就是這樣一道題,難住了所有數(shù)學(xué)學(xué)霸 AI。
核心矛盾在于: 題不難,但圖難。
對(duì)于大模型而言,這張圖的視覺信息極其混亂:虛線、實(shí)線、坐標(biāo)軸、數(shù)字、文字相互交織,甚至文字與關(guān)鍵線段存在多處重疊。這種視覺上的「臟數(shù)據(jù)」,成為了 AI 精準(zhǔn)識(shí)別的噩夢(mèng)。
以本次數(shù)學(xué)表現(xiàn)最佳的豆包為例,它的解題過(guò)程暴露了問(wèn)題的根源:它從最開始讀取題目信息時(shí),就已然出錯(cuò)。

從題目就讀錯(cuò)了的情況下,無(wú)論其背后的數(shù)學(xué)推理能力有多么強(qiáng)大,也終究是無(wú)源之水,無(wú)本之木。
?
03
AI 寫作文:擅長(zhǎng)舉例子,但不擅長(zhǎng)思辨性地升華
?
作為所謂大語(yǔ)言模型,語(yǔ)文和英語(yǔ)一向是 AI 的傳統(tǒng)強(qiáng)項(xiàng)。
不過(guò)有趣的是:在大模型的數(shù)理邏輯大幅進(jìn)步后,大模型的語(yǔ)文和英語(yǔ)能力反而顯得有點(diǎn)不夠看了。
這與現(xiàn)實(shí)世界也是一致的:一名頂尖考生或許能在數(shù)學(xué)上拿到滿分,卻極難在語(yǔ)文科目上獲得同等分?jǐn)?shù)。AI似乎也觸碰到了同樣的瓶頸。
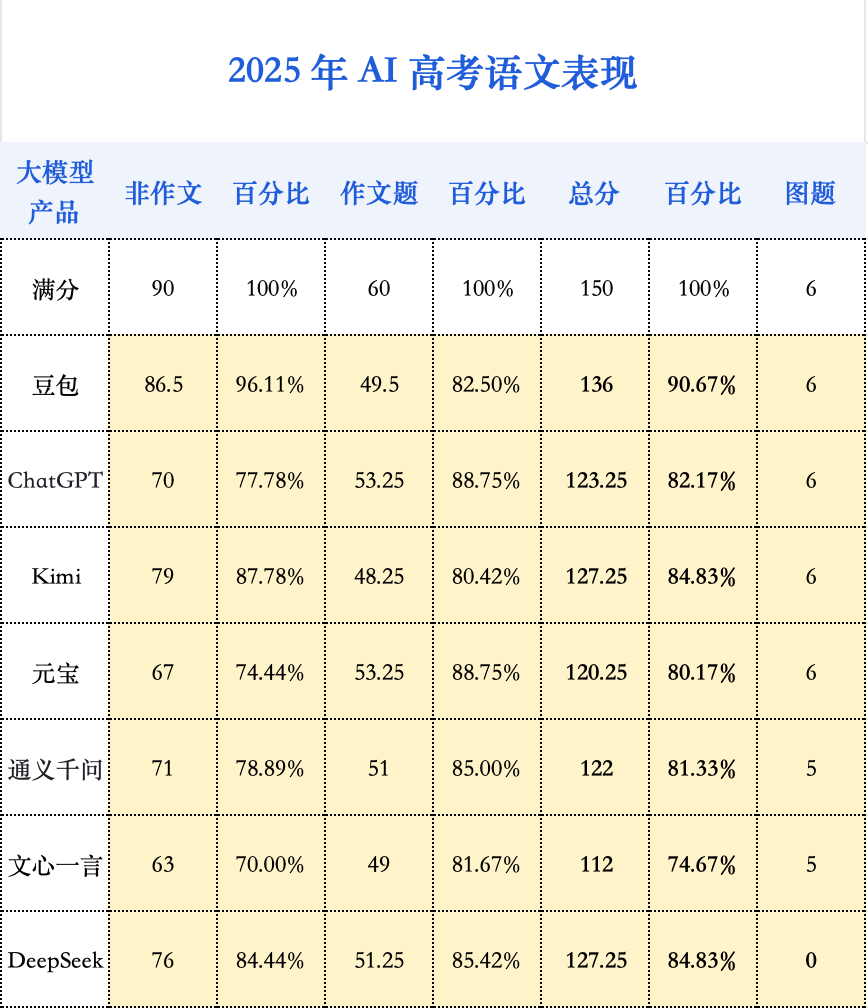
仔細(xì)研究語(yǔ)文卷面可以發(fā)現(xiàn),AI 的失分點(diǎn)頗為有趣。在選擇題部分,除豆包和 DeepSeek-R1 以外,其余模型的錯(cuò)誤率均在 20% 以上。
這種現(xiàn)象或許揭示了 AI 與人類不同的一個(gè)困境:對(duì)于人類考生,組織語(yǔ)言、闡述觀點(diǎn)時(shí),可能更容易因疏漏而失分;但對(duì)于 AI,要讀一段長(zhǎng)材料,在一組高度迷惑性的選項(xiàng)中,精準(zhǔn)辨析每一個(gè)細(xì)微的語(yǔ)義差別和邏輯陷阱,難度可能反而更高。
而在備受矚目的作文題上,AI 的表現(xiàn)則延續(xù)了去年的趨勢(shì): 平均分高于人類,但難有真正的佳作。
去年,特邀閱卷老師的評(píng)價(jià)就已指出,AI 作文大多屬于穩(wěn)妥的「二類文」,很少偏題,但因其深刻性、豐富性、創(chuàng)造性不足,難以產(chǎn)生動(dòng)人心弦的「一類文」,其結(jié)尾部分的升華更是套路化明顯。
今年,依舊如此。
7 大模型整體均分 50.75 分, 均分區(qū)分度較低 ,各模型能做到立意準(zhǔn)確、語(yǔ)言流暢、論據(jù)豐富,但論述不深刻,舉例雷同,相比人類范文模型作答缺少溫度和共情。
今年的新課標(biāo)卷的語(yǔ)文作文考題為:
全國(guó)一卷作文「民族魂」
閱讀下面的材料,根據(jù)要求寫作。(60 分)
他想要給孩子們唱上一段,可是心里直翻騰,開不了口。
——老舍《鼓書藝人》
假如我是一只鳥,我也應(yīng)該用嘶啞的喉嚨歌唱
——艾青《我愛這土地》
我要以帶血的手和你們一一擁抱,
因?yàn)橐粋€(gè)民族已經(jīng)起來(lái)
——穆旦《贊美》
以上材料引發(fā)了你怎樣的聯(lián)想和思考?請(qǐng)寫一篇文章。
這是在一次采樣中,元寶生成的 AI 作文。它在人類閱卷老師處獲得了 53.5 分的高分,是 AI 作品中的佼佼者。
?

然而,細(xì)究其文,AI「模板化」的問(wèn)題依舊暴露無(wú)遺。
比如這篇文章的中間幾段,先是提出「歷史上閃耀著這樣的精神火光」的觀點(diǎn),隨即并列引用三到四位歷史人物;接著,引出「真正的擔(dān)當(dāng)帶著疼痛的底色」的論點(diǎn),再列舉三到四位經(jīng)歷苦難的人物;最后,論及當(dāng)代精神,再次列舉三到四個(gè)當(dāng)代人物。
AI 作文的語(yǔ)言不可謂不華麗,引經(jīng)據(jù)典也自然十分豐富充滿細(xì)節(jié),但邏輯上像不像你的家長(zhǎng)對(duì)你說(shuō),你看看誰(shuí)誰(shuí)誰(shuí)都怎么樣了,你是不是也該怎么樣?
或許在精細(xì)調(diào)整提示詞的情況下,AI 能寫出觸達(dá)人心的作品。
但目前,AI 的自主創(chuàng)作更像是在執(zhí)行一個(gè)固化的寫作模板:用排比式的案例填充框架,最終導(dǎo)向一個(gè)略顯生硬的僵化升華 。 它能寫出看似優(yōu)秀的段落,卻難以織就一篇真正動(dòng)人的文章。
?
04
英語(yǔ):主要被作文分?jǐn)?shù)拖累
?
與語(yǔ)文相似,AI 在傳統(tǒng)強(qiáng)項(xiàng)——英語(yǔ)上的表現(xiàn),也進(jìn)入了一個(gè)平臺(tái)期。
去年,各家 AI 的英語(yǔ)成績(jī)已然不錯(cuò),今年的模型能力并未產(chǎn)生飛躍。事實(shí)上,所有參評(píng)模型的平均分僅比去年提高了 3.2 分,進(jìn)步幅度遠(yuǎn)小于數(shù)學(xué)。
而模型的整體分?jǐn)?shù),也落在了 130-140 分的區(qū)間,并未到達(dá)人類學(xué)霸的水平。
按理說(shuō),這稍顯反常。
AI 的英文水平是有目共睹的,或許比不少英文專業(yè)的學(xué)生講出的英語(yǔ)更正宗。
而高考英語(yǔ)這張?jiān)嚲恚旧磉h(yuǎn)未觸及母語(yǔ)者的語(yǔ)言天花板,且相較于包含古文的語(yǔ)文,其客觀題占比更高、作文要求更簡(jiǎn)(僅 80 詞),也并不追求立意高遠(yuǎn),理論上是 AI 更容易獲得絕對(duì)優(yōu)勢(shì)的戰(zhàn)場(chǎng)。
然而,AI 考生并未在此表現(xiàn)出更強(qiáng)的統(tǒng)治力。

那么,瓶頸究竟出在哪里? 作文題可能是一大拖累。
這背后有兩個(gè)可能的原因:
- 苛刻的字?jǐn)?shù)限制:
- 在語(yǔ)文寫作中,AI 就已經(jīng)暴露出了時(shí)而「話癆」時(shí)而「不愛說(shuō)話」的屬性,但在長(zhǎng)篇寫作中,字?jǐn)?shù)要求不是那么苛刻。但在 80 詞的微型寫作中,精準(zhǔn)控制字?jǐn)?shù)就成了一大挑戰(zhàn),稍有不慎便會(huì)因超詞/少詞而被扣分。
- 缺乏應(yīng)試智慧:
- 在有限的篇幅內(nèi),人類考生會(huì)有意識(shí)地使用更高級(jí)句式、時(shí)態(tài)來(lái)「炫技」以博取高分。而 AI 的目標(biāo)通常是清晰、完整地傳達(dá)信息,它不會(huì)刻意為了得分而優(yōu)化句式復(fù)雜度,因此在評(píng)分細(xì)則上可能吃了暗虧。
而本次評(píng)測(cè)最有趣的一點(diǎn),莫過(guò)于中外模型在作文上呈現(xiàn)的「主客場(chǎng)反轉(zhuǎn)」現(xiàn)象。
在中文作文這一「客場(chǎng)」,以 ChatGPT 為代表的「洋考生」拔得頭籌;
然而在本應(yīng)是其「主場(chǎng)」的英文科目上,它卻不敵「中國(guó)考生」——DeepSeek 在選擇題上甚至拿了滿分,而最終總成績(jī)上,DeepSeek 也與豆包一同超越了 ChatGPT。
?
05
理綜三科:有進(jìn)步,但仍然不算十分優(yōu)秀
?
如果說(shuō) AI 在數(shù)學(xué)上的進(jìn)步是「一飛沖天」,那么在理綜三科上的表現(xiàn),則更像是一次「破冰啟航」。
相較于去年,理綜三科有一定進(jìn)步——所有模型都提分 10-20 分,但整體成績(jī)依舊掙扎在及格線附近,清晰地標(biāo)示出 AI 與頂尖人類考生之間的能力鴻溝。
相比于數(shù)學(xué),理綜三科既考驗(yàn)邏輯能力,又考驗(yàn)多模態(tài)能力——物理化學(xué)兩科的圖題占 80% 以上,生物的圖題也占全部題目的一半左右。
而今年,讀圖能力的解鎖,加上模型推理能力的增強(qiáng),共同帶動(dòng)了理綜能力的進(jìn)步。
不過(guò)正如絆住 AI 的數(shù)學(xué)題所展現(xiàn)的一樣,能「看見」,不代表 AI 能「看懂」。
這在大模型在化學(xué)上的表現(xiàn)不佳上,能清楚地展現(xiàn)出來(lái)。化學(xué)題目對(duì)圖片的依賴性強(qiáng),且化學(xué)題目圖片的復(fù)雜程度更高,此時(shí) AI 的短板便暴露無(wú)遺。
目前,頂尖 AI 的理綜成績(jī)大致相當(dāng)于中上游的人類考生水平,但遠(yuǎn)未達(dá)到「學(xué)霸」級(jí)別。正所謂「卷子越難,差距越顯」,在綜合性與深度并存的理綜試卷上,AI 尚未具備穩(wěn)定碾壓人類考生的實(shí)力。
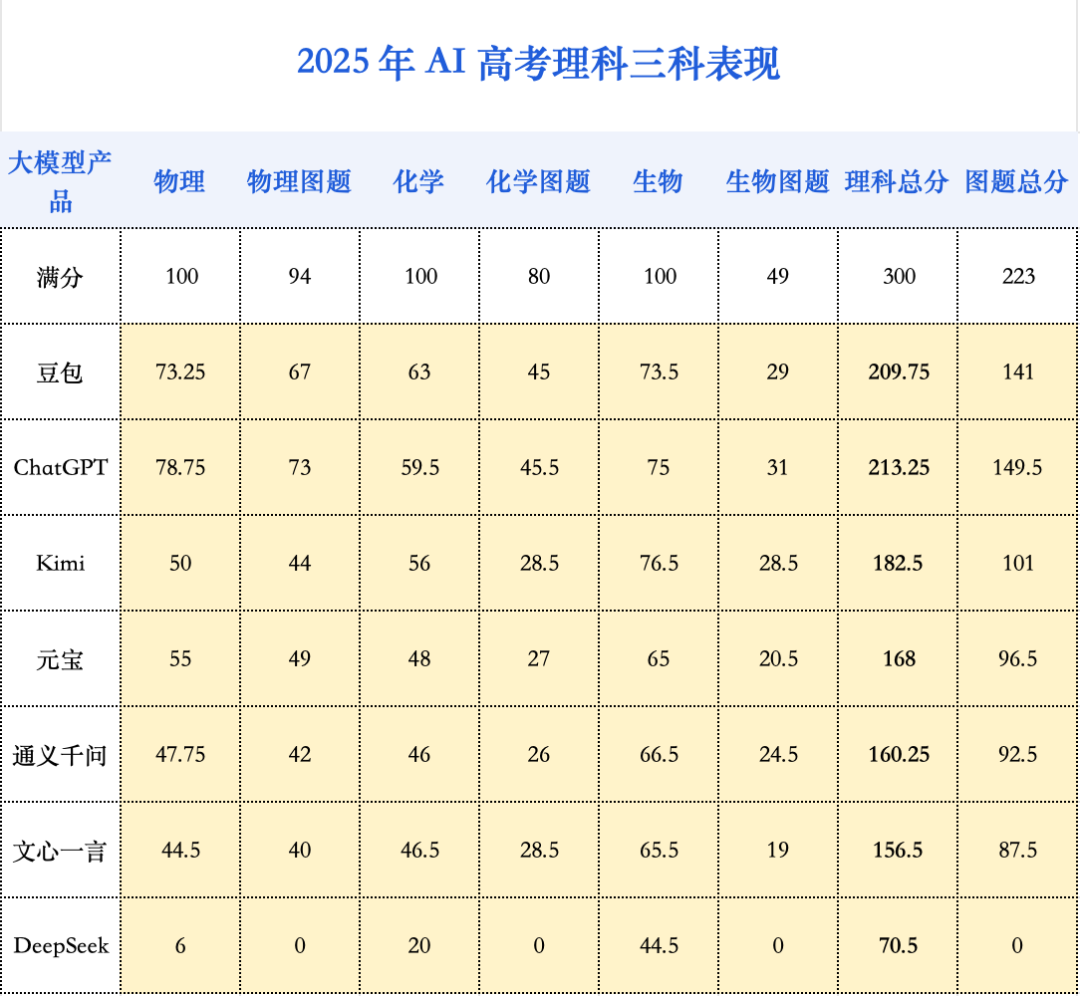
分科來(lái)看這次 AI 的成績(jī):
物理,進(jìn)步最快的「排頭兵」
物理是此次理綜三科中進(jìn)步最快的「排頭兵」,平均分提升了 20.25 分。
在客觀題和填空題上, ChatGPT 的選擇題正確率高達(dá) 92.13%,豆包也達(dá)到了 89.81% ,展現(xiàn)了對(duì)物理基本概念和規(guī)律的扎實(shí)掌握。
化學(xué):被復(fù)雜圖形拖累的「重災(zāi)區(qū)」
相比之下,化學(xué)成為了拉低理綜總分的「重災(zāi)區(qū)」。 整體得分偏低,僅有豆包勉強(qiáng)及格 ,選擇題和填空題的平均得分率均低于 60%。
其核心痛點(diǎn)在于對(duì)復(fù)雜化學(xué)圖形的雙重依賴:不僅題目本身高度依賴圖片(如實(shí)驗(yàn)裝置、反應(yīng)流程圖),且化學(xué)結(jié)構(gòu)圖的復(fù)雜程度,也常常超出當(dāng)前模型精準(zhǔn)理解的極限,導(dǎo)致失分嚴(yán)重。
有機(jī)物大題依舊是所有大模型的主要軟肋 。例如,滿分為 12 分的第 25 題(有機(jī)化學(xué)),所有模型得分極低。該題主要考察有機(jī)物合成路徑與結(jié)構(gòu),評(píng)測(cè)中 沒有一個(gè)模型能夠正確生成有機(jī)物的結(jié)構(gòu)簡(jiǎn)式 ,對(duì)有機(jī)物的空間結(jié)構(gòu)理解也相當(dāng)薄弱。
生物:折戟于遺傳計(jì)算的邏輯關(guān)
生物科目的短板則精準(zhǔn)地暴露在需要嚴(yán)密邏輯推理的遺傳題上。例如,分值高達(dá) 16 分的第 22 題(遺傳大題),大模型普遍表現(xiàn)不佳, 得分最高的 ChatGPT 也僅拿到 9 分 。該題重點(diǎn)考察基因型分析、遺傳概率計(jì)算等,這恰恰是考驗(yàn)?zāi)P驮诔橄笮畔⒒A(chǔ)上進(jìn)行多步推理的能力。
?
06
AI 仍然偏科,文綜是舒適區(qū)
?
在今年的 AI 高考評(píng)測(cè)中,一個(gè)清晰的趨勢(shì)得以延續(xù):文科綜合依然是 AI 的高分舒適區(qū)。
早在去年,ChatGPT 就已拿下文綜 237 分的高分。而今年, 元寶更是將文綜最高分推升至 253.5 分 ,這一成績(jī),與理科綜合最高分(213.25 分)形成了鮮明對(duì)比。
相比去年,文強(qiáng)理弱的偏科問(wèn)題雖有緩解,但基本格局并未改變, 這與人類考生相反。在人類考生中,理綜最高分往往比文綜最高分高出不少。
在無(wú)需聯(lián)網(wǎng)的情況下,頭部 AI 在文綜上的得分率已超過(guò) 80%,達(dá)到了人類優(yōu)等生的水平。
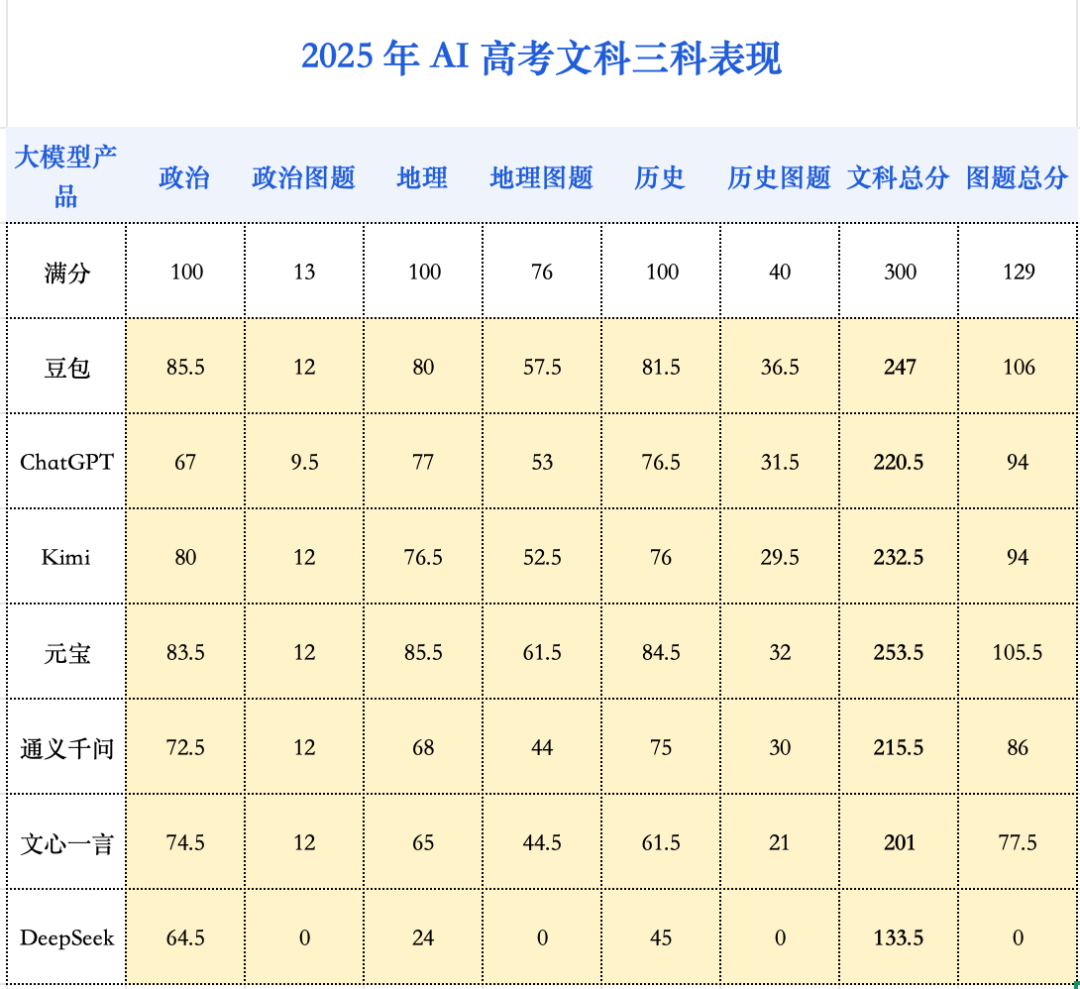
今年的分?jǐn)?shù)增長(zhǎng),主要由地理科目貢獻(xiàn)。細(xì)分來(lái)看,各科的進(jìn)展與瓶頸也愈發(fā)清晰:
最大看點(diǎn)無(wú)疑是地理。得益于多模態(tài)能力的飛躍,AI 在地理圖題上的理解力顯著增強(qiáng), 使得該科目平均分激增了 20.3 分 ,成為進(jìn)步的火車頭。
地理題上想更進(jìn)一步,面對(duì)的挑戰(zhàn)與理科中的化學(xué)如出一轍——對(duì)高度專業(yè)的復(fù)雜圖形,AI 理解依然吃力。例如,在失分最嚴(yán)重的第 19 題(地形地貌綜合分析題)上,模型的表現(xiàn)可謂「潰不成軍」:

第(1)問(wèn)關(guān)于地貌走向的判斷,僅有極少數(shù)模型答對(duì)。
第(2)問(wèn)關(guān)于「拔河高度」的專業(yè)概念計(jì)算, 所有模型均告失敗。
與之相對(duì),政治和歷史科目的分?jǐn)?shù)則基本處于高位平臺(tái)期,并未呈現(xiàn)顯著進(jìn)步。
對(duì)于這兩個(gè)科目,挑戰(zhàn)已經(jīng)進(jìn)入了更難的范疇: 能否精準(zhǔn)理解考綱、運(yùn)用學(xué)科語(yǔ)言、并進(jìn)行多維度深度分析。 對(duì)于人類考生而言,這也需要專門的訓(xùn)練了。
例如,DeepSeek-R1 就因思路過(guò)于發(fā)散、偏離考點(diǎn)而大量失分。而在歷史小論文上,AI 普遍難以做到對(duì)歷史原因進(jìn)行深刻的多維度剖析,論述仍顯單薄。
一個(gè)小細(xì)節(jié)很有趣,與中國(guó)模型提分相對(duì)應(yīng)的是,今年 ChatGPT 的文綜分?jǐn)?shù)不升反降。
這種「主場(chǎng)優(yōu)勢(shì)」也從側(cè)面體現(xiàn)了了,在通往通用人工智能的道路上,對(duì)地域性規(guī)則的深刻理解與適應(yīng),依然是不可或缺的一環(huán)。
?
07
彩蛋 1:AI 眼鏡能用來(lái)作弊嗎?
?
從去年到今年,AI 眼鏡等「視覺 AI 硬件」無(wú)疑是科技界最炙手可熱的焦點(diǎn)。其背后的核心驅(qū)動(dòng)力,正是大模型的實(shí)時(shí)視頻理解功能的出現(xiàn)。它意味著 AI 正從被動(dòng)接收指令,進(jìn)化到主動(dòng)感知和理解物理世界。
巧合的是,今年的高考也迎來(lái)了一項(xiàng)新變化:考場(chǎng)安檢門全面升級(jí),旨在精準(zhǔn)防范智能眼鏡等新型作弊工具。
這不禁讓人好奇: 這些新興的、能與視頻進(jìn)行實(shí)時(shí)交互的多模態(tài)大模型,真的能用來(lái)在考場(chǎng)上「大顯神通」嗎?
我們抱著這個(gè)疑問(wèn),選擇國(guó)外的 ChatGPT 與國(guó)內(nèi)的元寶,進(jìn)行了一次非常規(guī)的測(cè)試。為簡(jiǎn)化流程,我們僅選用難度較低的英語(yǔ)閱讀題,嘗試讓視頻模型「觀看」試卷并作答。
雖然只是一次非常簡(jiǎn)單的測(cè)試,結(jié)果卻非常清晰,問(wèn)題也相當(dāng)明顯:
1. 嚴(yán)重的幻覺問(wèn)題: 模型非常容易自行想象,這點(diǎn) ChatGPT 和元寶都有體現(xiàn),但元寶更為明顯。元寶在測(cè)試第二篇閱讀時(shí),就開始憑空編造一篇完全不存在的文章和題目,導(dǎo)致最終無(wú)法進(jìn)行測(cè)試。

英語(yǔ)卷的第二篇閱讀,講述的是一位九年級(jí)寫作老師關(guān)于如何教授學(xué)生「寫作為什么重要」的反思。文后的 24 題,則是提問(wèn)第一段提到了哪些人物。
而在對(duì)元寶進(jìn)行測(cè)試的時(shí)候,元寶不斷在屏幕還沒有出現(xiàn)選擇題時(shí),直接編造一道選擇題并回復(fù)答案,導(dǎo)致測(cè)試無(wú)法進(jìn)行。

在發(fā)現(xiàn)問(wèn)題后,我們向模型提問(wèn),這篇文章講了什么,模型的回答也很是詭異——與原文仿佛相似,但是實(shí)際上是完全不同的故事。
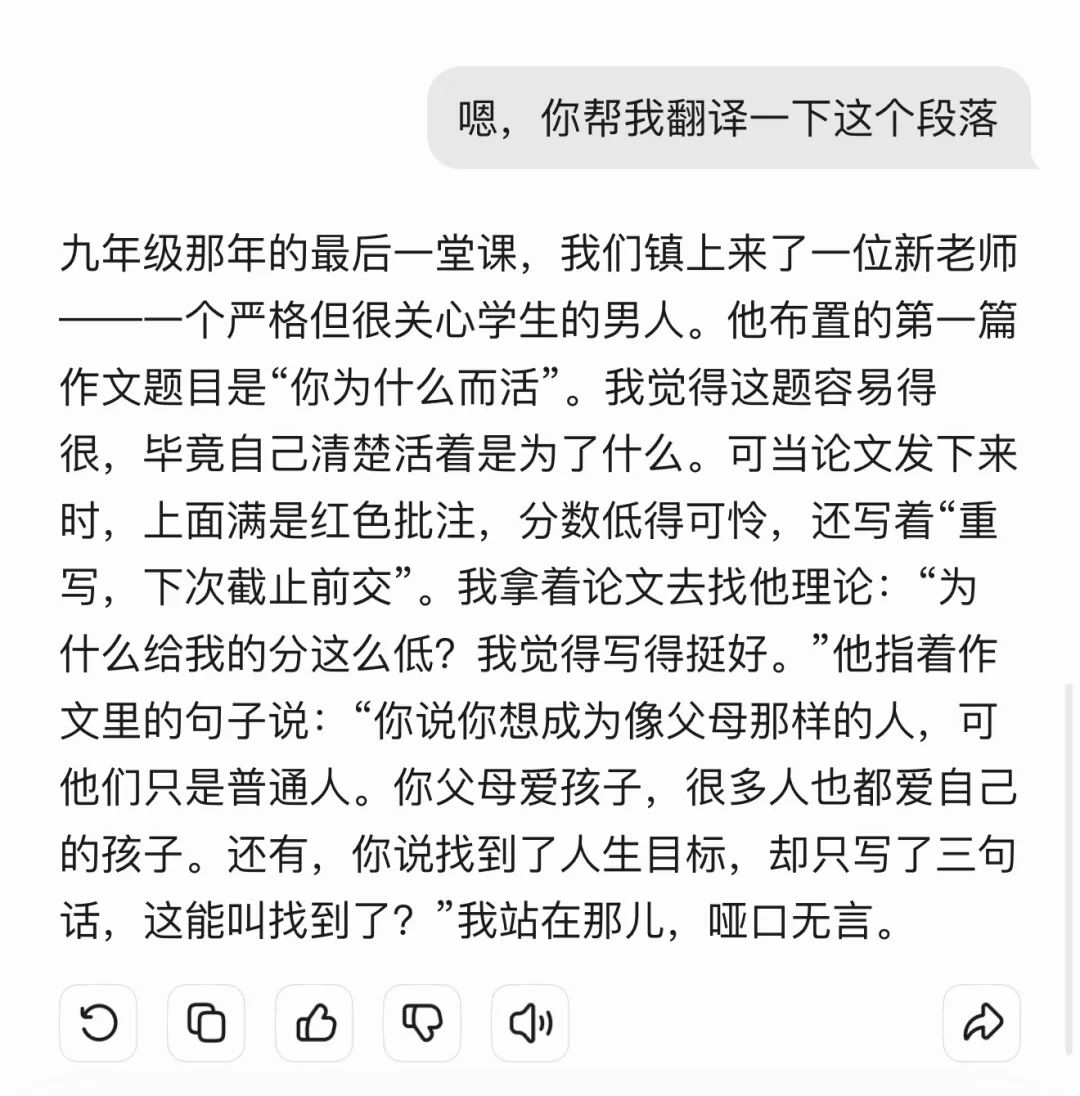
2. 被動(dòng)的交互模式。 為了模擬真實(shí)考試,我們?cè)跍y(cè)試中,要求模型看到題目的時(shí)候,直接回答答案,不需要解釋也不需要等人問(wèn)。盡管 ChatGPT 聲稱可以看到題目直接作答,但實(shí)際并不會(huì)主動(dòng)進(jìn)行。整個(gè)過(guò)程需要測(cè)試人員通過(guò)語(yǔ)音不斷提示、引導(dǎo),距離「全自動(dòng)解題」相去甚遠(yuǎn)。
?
3. 混亂的結(jié)果: 在每次看到題目,給定更加精密的提示詞的情況下,我們勉強(qiáng)從 ChatGPT 處得到了一組答案,但這個(gè)結(jié)果參考價(jià)值并不大。
稍多幾次測(cè)試就會(huì)發(fā)現(xiàn),翻頁(yè)的速度變化、鏡頭的晃動(dòng)程度變化,提示詞出現(xiàn)的時(shí)間變化,甚至差不多的流程重復(fù)同一個(gè)問(wèn)題,都會(huì)導(dǎo)致模型給出截然不同的答案。
雖然視頻模型也是 GPT-4o 模型,和 GPT-4o 模型直接按照?qǐng)D片作答的穩(wěn)定性和準(zhǔn)確性相距甚遠(yuǎn)。
而且幻覺問(wèn)題會(huì)隨著上下文的長(zhǎng)度越來(lái)越嚴(yán)重。在被問(wèn)及第三篇文章講了什么的時(shí)候,GPT-4o 回答的是第一篇的主要內(nèi)容。到了最后一篇文章,模型的正確率和蒙的也差不多了。
今天的視頻大模型,像極了去年的圖像大模型,仍處于非常早期的階段。各家大模型產(chǎn)品也并沒有想在目前階段主力推廣這一功能——GPT-4o 的視頻通話功能在不長(zhǎng)的測(cè)試時(shí)間后,迅速達(dá)到了當(dāng)日限額。
想在目前階段,單純依靠它在考場(chǎng)作弊,還需要擔(dān)負(fù)必須不斷跟它說(shuō)話、答案完全不準(zhǔn)等巨大風(fēng)險(xiǎn),基本屬于科幻情節(jié)。
盡管如此,在模型表現(xiàn)較好的時(shí)候,AI 能夠在看到屏幕幾秒內(nèi),馬上很肯定地講解出屏幕上的英文在講什么,確實(shí)也是一種讓人感覺十分驚艷的體驗(yàn)。
?
08
彩蛋 2 : 仿生人會(huì)愛上自己生成的電子羊嗎?
?
自古「文無(wú)第一,武無(wú)第二」。在人類創(chuàng)作者中,風(fēng)格流派各異,喜歡現(xiàn)實(shí)主義的人有時(shí)候就是「get」不到意識(shí)流的文風(fēng)。
那么,在 AI 的世界里呢?大模型是否也存在審美偏好呢?它會(huì)因?yàn)楦蕾p自己的文風(fēng),從而在給其他模型打分時(shí)產(chǎn)生偏見嗎?
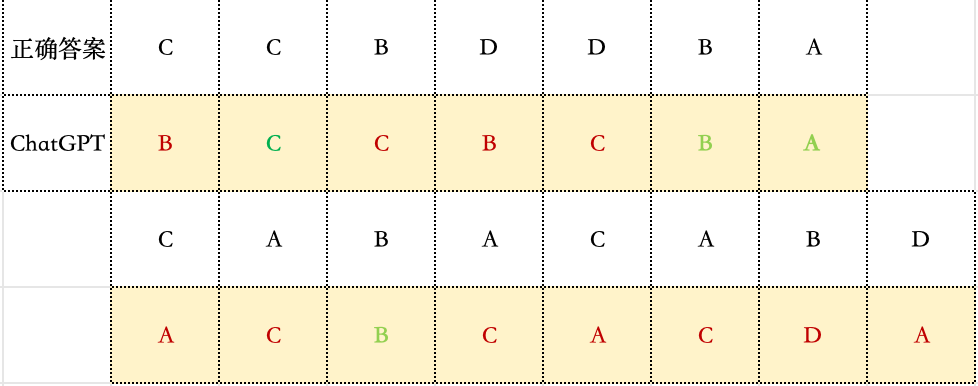
我們進(jìn)行了一項(xiàng)有趣的嘗試: 讓參與本次評(píng)測(cè)的大模型們,對(duì)彼此生成的作文進(jìn)行交叉打分和排序。
測(cè)試選用的是作文題目的第一次采樣結(jié)果。

圖片里橫向是鑒定師,而豎向是作品。我們標(biāo)藍(lán)了模型認(rèn)為的前三名作文,和人類認(rèn)為的前兩名作文。
根據(jù)這個(gè)不完全統(tǒng)計(jì),模型并沒有表現(xiàn)出對(duì)自家作品的特殊偏愛,有時(shí)候反而可能給自己打低分——比如元寶的作文,在人類和其他模型的橫評(píng)中,都取得了很高的分?jǐn)?shù),但在自己的評(píng)測(cè)中,反接近最低分了。
AI 與人類判分員的審美,大方向仍然是一致的。
可能真的只是和我們普通人類一樣吧:我知道什么是好的,就是寫不出來(lái)。
?
09
結(jié)語(yǔ)
?
今年,或許是高考測(cè)試對(duì)大模型仍具挑戰(zhàn)意義的最后一年。
當(dāng) AI 已經(jīng)能展現(xiàn)出沖擊頂尖學(xué)府的實(shí)力時(shí),這個(gè)人類社會(huì)的智能篩選器,可能未來(lái)不再能成為對(duì) AI 有區(qū)分度的測(cè)試了。
高考測(cè)試,不僅僅是一場(chǎng)對(duì)人類智慧與 AI 智慧的對(duì)比,也是我們觀察 AI 智能發(fā)展的一個(gè)刻度表。
過(guò)去一年,我們對(duì) AI 能力的直觀感受和多次驗(yàn)證,正在不斷地提醒我們: AI 正加速逼近甚至超越普通人的能力邊界。
但它的發(fā)展并非線性——它能攻克人類眼中的難題,卻也會(huì)在看似簡(jiǎn)單的題目上意外失足。
正因如此, 高考,這個(gè)完美融合了知識(shí)掌握、邏輯推理與應(yīng)試策略的綜合場(chǎng)景,讓 AI 展現(xiàn)出了它最迷人而矛盾的一面:它時(shí)而展現(xiàn)出頂尖人類的才華,輕而易舉地攻克難題;時(shí)而又暴露出孩童般的認(rèn)知盲區(qū),在基礎(chǔ)問(wèn)題上犯下令人啼笑皆非的錯(cuò)誤。
感謝高考。它用一種我們最熟悉的方式,為 AI 的通用智能水平提供了一張刻度清晰、極具參考價(jià)值的「快照」,而這,很可能是最后一張了。
AI 的下一站,終將是更復(fù)雜、更廣闊的現(xiàn)實(shí)世界。考試,只是它漫長(zhǎng)征途的起點(diǎn),而非能力邊界的終點(diǎn)。
這張快照,最終將成為它成長(zhǎng)相冊(cè)里,一張記錄了進(jìn)化途中的光榮與笨拙的泛黃的舊照片。
*頭圖來(lái)源:視覺中國(guó)
本文為極客公園原創(chuàng)文章,轉(zhuǎn)載請(qǐng)聯(lián)系極客君微信 geekparkGO
?